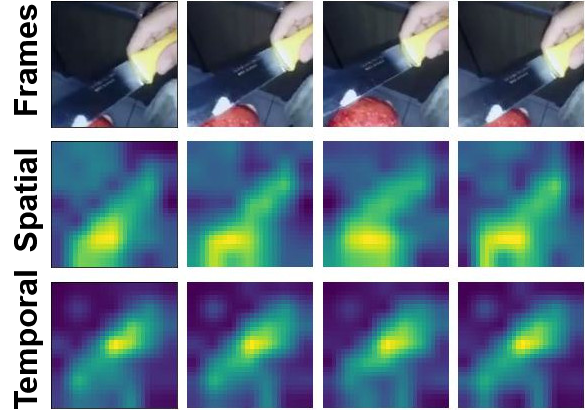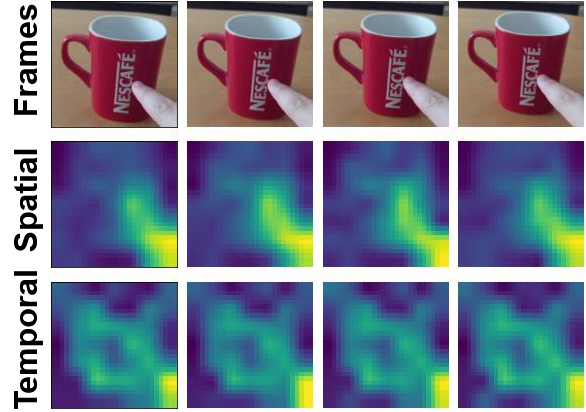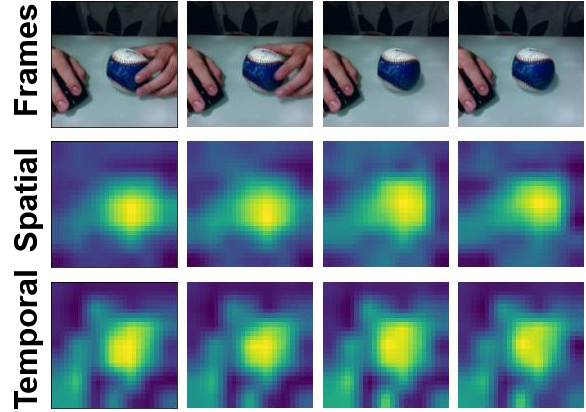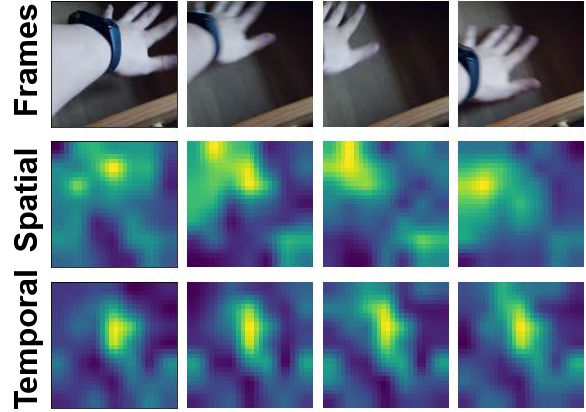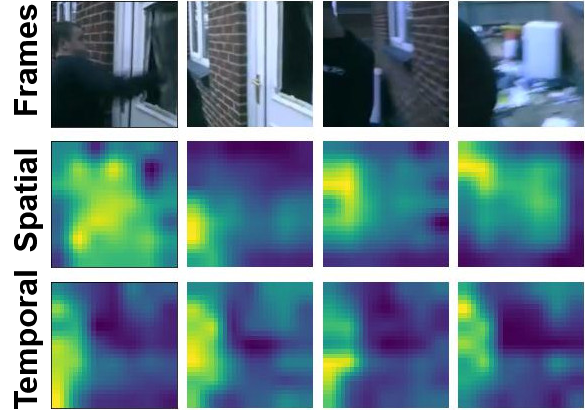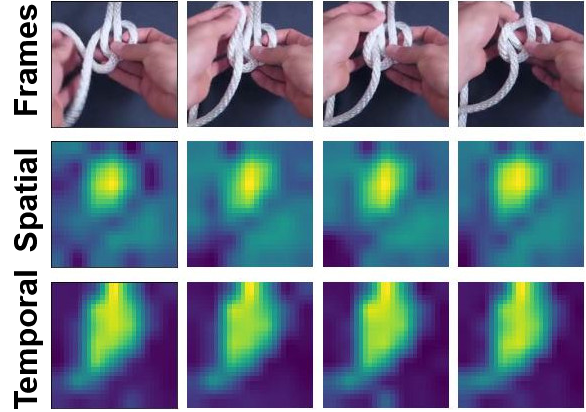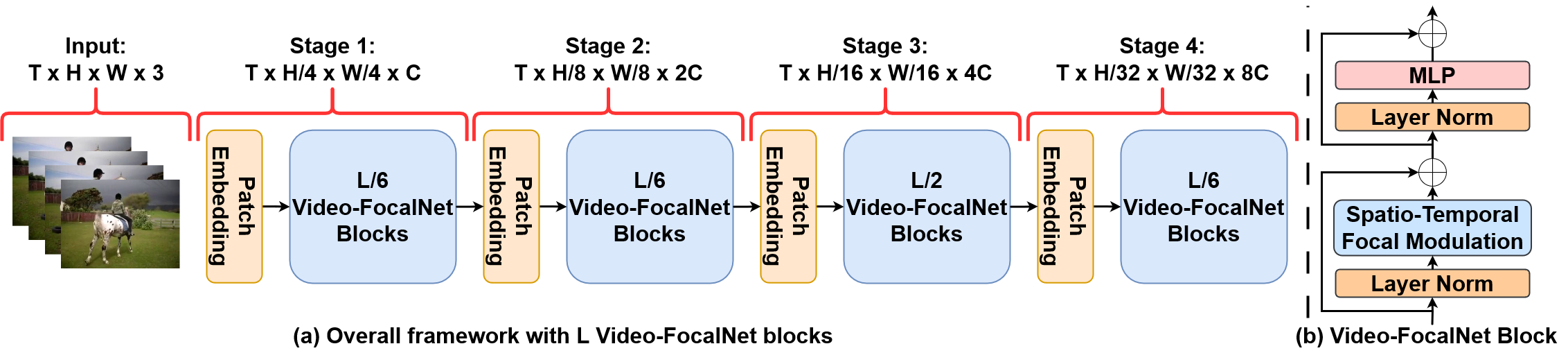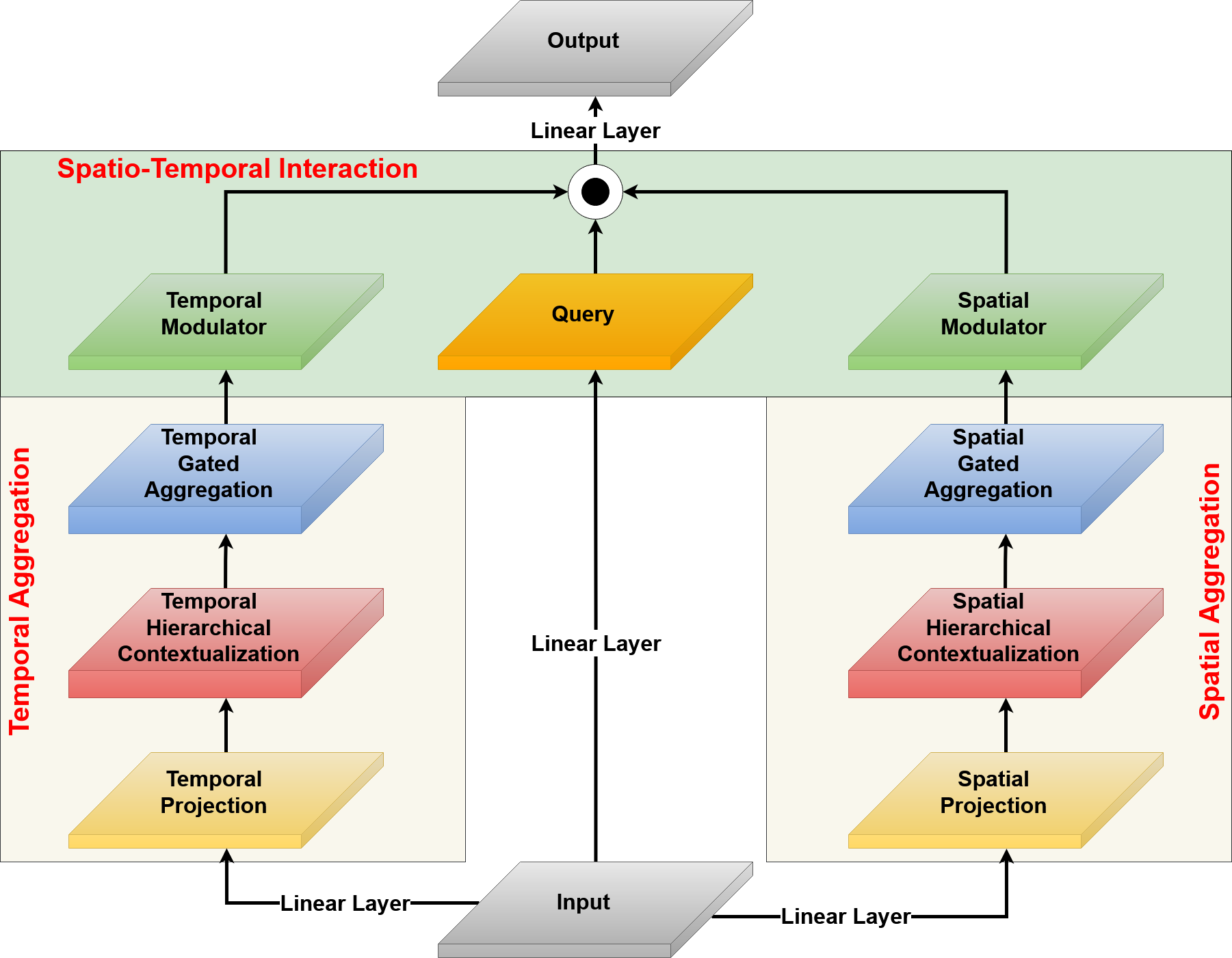
Visualizations
We visualize the spatial and temporal modulators for sample videos from Kinetics-600 and Something-Something-V2. Note how the temporal modulator fixates on the global motion across frames while the spatial modulator captures local variations.